We believe Use-Case Optimization will be the future of L1s. Given the trilemma, no chain can achieve one-size-for-all status. Building on our previous cross-chain essay, we propose a three-question playbook for builders to consider their tech choices.
We have more ideas than the space allowed here. We cordially invite interested builders and investors for further discussion. Find us here, on Twitter @TheAntiApe, or through email at theantiape@gmail.com
Until now, Solana has a monopoly as the only high-performance chain.
Solana’s design DNA is aggressive optimization for best-case performance: parallelism, redundancy reduction, and higher block rates.
What’s sets Solana apart
As the only blockchain to approach Visa’s 65,000 TPS capacity, Solana has garnered support from Wall Street and Silicon Valley alike to experiment with mass-accessible blockchain services.
Solana didn’t achieve the TPS with some Turing-award magic (unlike zero-knowledge proofs, another canonically important topic we will cover soon). Rather, Solana made a series of design trade-offs between performance and reliability. We’ll discuss Solana’s performance recipe in Section 1 and reliability costs in Section 2.
Design Choice 1: Parallelism. The Ethereum virtual machine (EVM) is single-thread — EVM can only utilize one CPU core to process transactions sequentially. Because single cores generate exponentially more heat as speed goes up, physics imposes a very low cap on single-core performance.
The solution? More cores! Eight 2GHz cores are much cooler, yet more powerful, than one 8GHz core. In 2007, Intel introduced the dual-core Pentium, effectively ending the single-core era. Consumer GPU and CPUs today have anywhere between 4 to 4096 cores. Making more cores collaborate better, instead of having stronger single-core, has been the focus of the semiconductor industry for more than a decade.
To be natively multi-thread, Solana has to forgo EVM compatibility. Solana’s smart contracts can utilize Nvidia GPU’s 4096 cores to run computations in parallel.
Our take: In this [EVM v. Multi-thread] binary choice, we lean towards multi-thread over EVM compatibility. We think it’s absurd for a 2027 dApp to be trapped in 2007 semiconductors.
Some may point to EVM/Solidity developer moat. But developers switch programming languages quite easily. Most Web 2 programs and developers today are natively multi-thread. We think future developers will be as frustrated with EVM’s arcane single-thread architecture as gas-payers. (By extension, we are not the biggest fans of EVM compatible rollups either.)
Design Choice 2: Reducing redundancy by deterministic leader rotation
Decentralization requires redundancy. With centralized clouds like Google, computation happens exactly once — users trust Google to be correct.
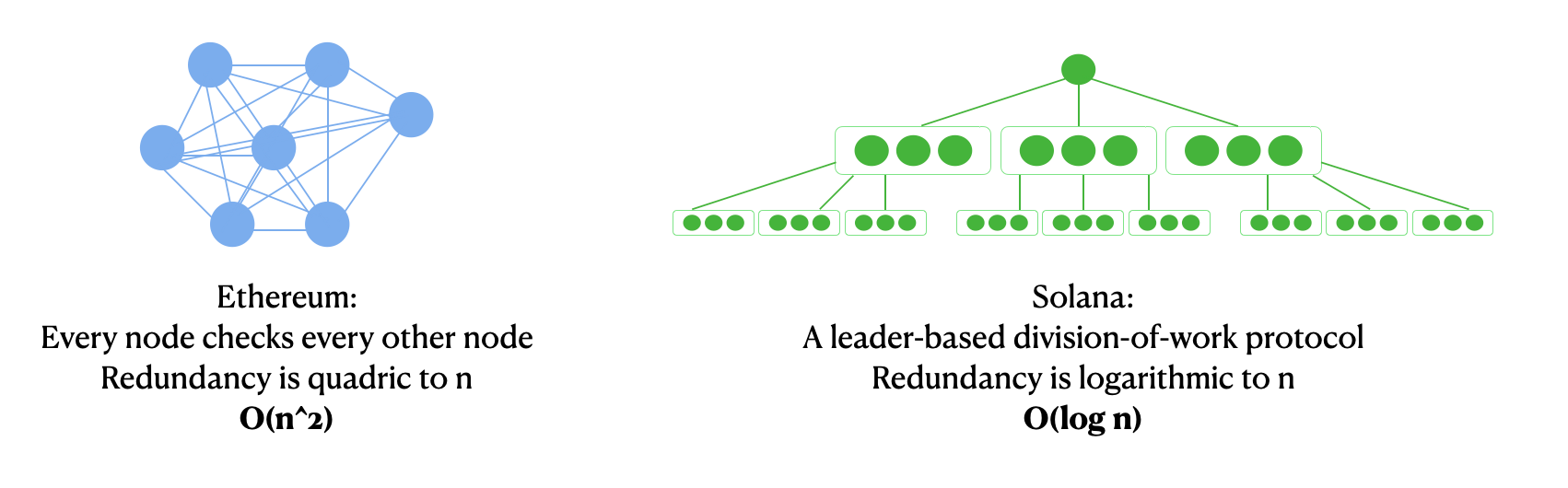
With blockchains, since we cannot trust anyone, all data need to be computed and verified by different nodes. The extra times an identical computation is done is the overhead/redundancy. To quantify redundancy, we use Big-O notations like [O(n^2), O(n), O(log n)], where the function inside indicates how complex the network computation will be as they scale to more nodes. For example, O(n^3) can mean orders of magnitude greater redundancy than O(n^2) as the network grows.
With Bitcoin, Ethereum, and many other simple PoS chains, the redundancy of consensus is at least O(n^2), proportional to the number of nodes squared: every block has to transmit, check and compare the work of every other block.
With Solana, only the one designated leader will make the next block. (See Gulf Stream, Leader Rotation). On top of that, instead of having nodes send and verify full blocks among one another, Solana splits blocks into pieces and has a small group of nodes validate each piece. (See Turbine)
Solana’s protocols reduce Solana’s best-case redundancy from O(n^2) to O(log n), the most efficient possible in computational complexity theory. The result is truly remarkable. Consider an (oversimplified) illustration:
Network A & B are otherwise identical with 100k TPS at 100 nodes.
A O(n^2) network’s performance will decay 100x every 10x node growth.
A O(log n) network will only decay ~3x every 10x node growth.
At 100,000 nodes, the two networks’ performance will be 30000 times apart.
This complexity reduction also has ideological significance. In this regard, we believe Vitalik’s criticism of Solana is somewhat misguided — Vitalik thinks Solana is not sufficiently decentralizable because of high hardware requirements. Solana’s $4000 USD hardware cost stops “every user [from] running Solana on their own machines”. The cost is true. But in the long run, computing will get cheaper, and Solana’s complexity-reduction design makes it possible to have 100x more nodes without rendering the network unbearably slow.
Other Design Choices: Supporters and critics also debate a few other technical features of Solana. We consider these features less central, so we summarily discuss:
3.1 Voting counted in TPS: Some critics say Solana artificially bolsters TPS numbers by counting validator votes as transactions. It’s true that votes are counted as TX. But it’s a cosmetic issue. Probably Solana should’ve claimed a headline TPS of 60,000 instead of 65,000, excluding votes.
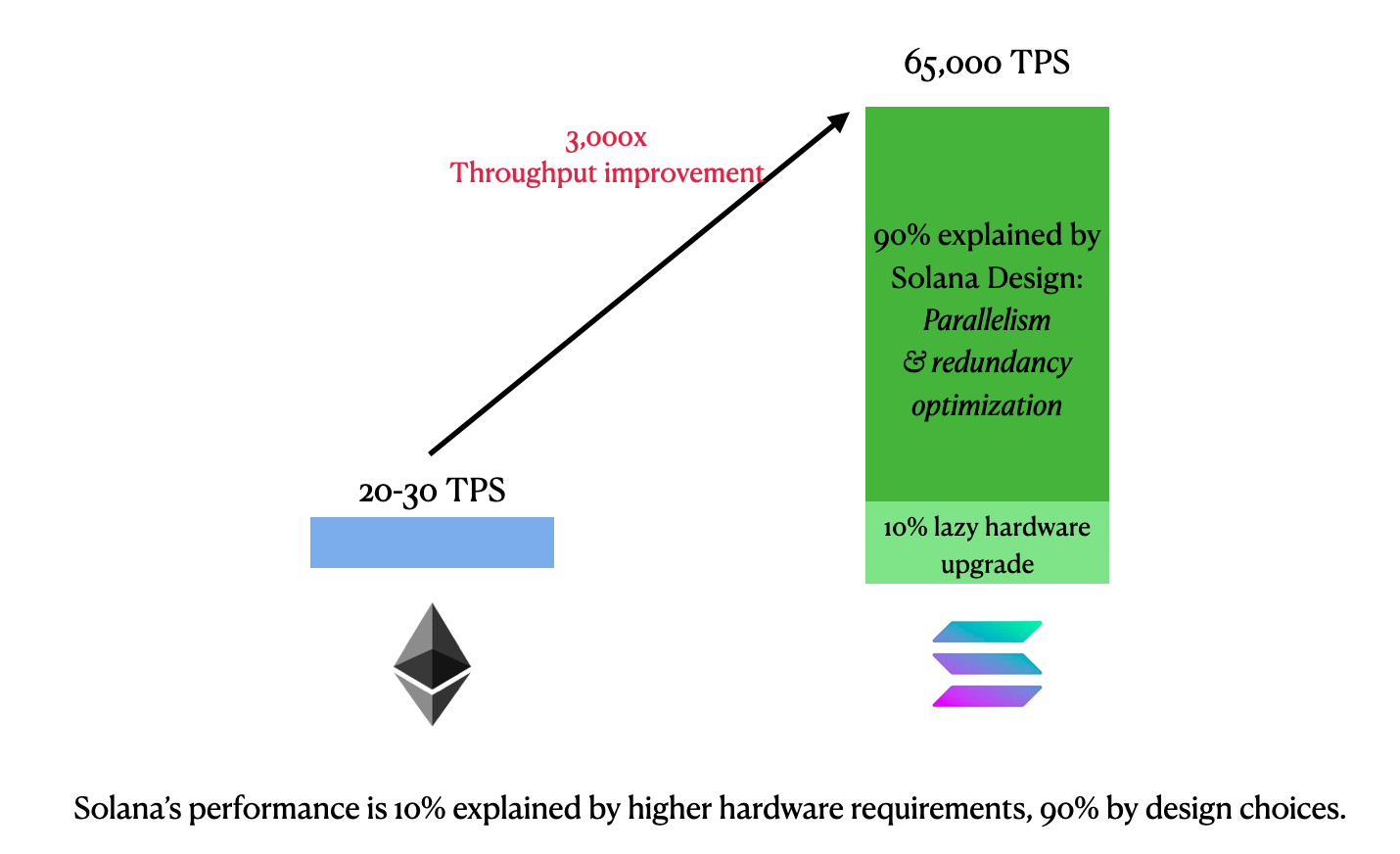
3.2Throughput with faster block time and bigger blocks: Both Vitalik and StarkWare criticized Solana’s performance improvement as somewhat lazy, in the sense that Solana merely made each block bigger and block time shorter to accommodate more transactions at the cost of higher hardware requirements. Simple math would tell you this is not the entire picture:
Before overhead, the combination gives Solana a roughly 300x “lazy” performance enhancement over Ethereum.
But Solana’s TPS is 3,000 times higher than ETH’s typical TPS. The other 90% is better explained by Solana’s parallelism and redundancy reduction as we discussed.
3.3 Proof of History. Solana advertised PoH as its biggest innovation. Putting things into perspective, Proof of History allows Solana to reduce block time to an extreme 400ms/block despite the fact physical network delays are often bigger than 400ms. The fancy name for this feature is asynchronistic consensus, see a Multicoin writeup for more details.
Three key metrics collectively determine the max throughput of a blockchain: block rate, parallelism, and redundancy.
Redundancy determines how much total data and compute is needed, that is, Total compute = payload + redundancy;
Parallelism allows nodes to compute faster;
Block rate limits the amount of data that can be saved in the blockchain database in a given period.
Solana has made bold design choices with all three: from O(n^2) to O(log n) redundancy; from 1 core to 4096 cores parallel, and from 5MB/min to 1500MB/min block rate. These are the main recipe behind Solana’s 65,000 TPS. In the next chapter, we will discuss the cost of Solana’s choices.
Section 2: The cost of Solana’s choices: prioritizing performance over resilience
In this Section:
Solana’s aggressive performance-optimized DNA makes it more prone to outages than other blockchains.
We present the Redundancy Dilemma: given limited computational power, L1s have to make a trade-off between performance and reliability.
The redundancy dilemma is a subset of the High-Performance Trilemma in Section 3.
What’s the nature of the root cause? A one-off bug? Surprise attacks? Something in the chain’s DNA we can only mitigate?
Choosing best-case performance over reliability
In Section 1, we discussed how Solana aggressively optimized its best-case performance. “Best-case” is the operative word here. Solana goes haywire when things don’t exactly happen in the ideal pattern.
Design Cost 1: Aggressive parallelization degrades when transactions are logically sequential.
NFT mint and IEO trades often break Solana. One of the top reasons: these transactions cannot happen at the same time on 4096 cores. Minting NFTs without knowing what has been minted will lead to duplication and bugs. All minting transactions from the same collection must be handled sequentially. An immediate implication is that Solana’s 65,000 TPS doesn't mean users can mint 6 BAYC collections in one second: relying on only one GPU core (or GPU multiprocessor), Solana’s sequential processing power is probably closer to Ethereum, in the ballpark of 10s to 100s TPS.
This explains performance degradation: runaway volume on NFT mints would make Metaplex unusable, but other programs not dependent on Metaplex (like Serum order books) can still process on one of the other 4095 cores.
But more often, degradation becomes outage: unprocessed volume waiting for Metaplex swarms leader nodes out of memory — when out of memory, nodes crash and go offline altogether.
The core trade-off: by using 4096-core GPUs instead of 16-core CPUs, Solana sacrifices single-core performance in favor of aggressive parallelism. Normally, things run well when transactions are unrelated, but once they exhibit undesirable patterns, Solana is much more likely to break than a high-redundancy Ethereum.
When Solana is close to breaking, the current block leader is often the first to crash. Solana’s low-redundancy design depends heavily on the leader being online — no other node has the same tx data or network role as the current leader. This means once the leader goes offline, the rest of the network needs to do a lot of contingency work: agreeing on skipping a block, reorganizing transactions, and forwarding the lost transactions to the next leaders …
Consider Ethereum, in which there is no leader, every node has an exact and duplicate copy of the next transactions to be put in a block (the mempool). If any Ethereum node goes offline, all other nodes still have at hand all they need to produce a new block. This is the double-edged sword of redundancy: redundancy is slow and irritating during good times, but it can prevent major trouble during bad times.
Let’s put it in numbers. According to this paper, in the crashing leader case (formally called “cascading leader failure”), Solana’s emergency overhead can reach O(n^4). An O(n^2) network is slow but usable, yet an O(n^4) network is good as dead. That’s the main reason why Solana has so many network restarts — it can hardly recover on its own once in O(n^4) cascading leader failure mode.
It’s a feature, not a bug
The DNA of Solana is aggressive best-case performance. This principle is everywhere in the architecture so it’s hard to just change one place without also changing everything else. (We didn’t discuss this but, just to illustrate interdependencies, the core PoH algorithm would be impractical if run on CPU instead of GPUs, and Solana’s PoH-best-case-optimized data management system makes it difficult to implement an ETH-like mempool). Again, it’s a trade-off and one cannot have it both ways — to fundamentally make Solana more stable requires creating more redundancy, thus sacrificing best-case performance.
Even a Solana supporter should expect outages and degradation to happen many more times because Solana today is far from having tried all mitigations possible. Mitigations are ultimately an iterative hide-n-seek. One day the hard work of Solana Labs may make 99.99% uptime possible. But it was never meant to be 100%, and the mainnet beta today is far away from 99.99%.
Section 3: Aptos joins the competition and the high-performance trilemma
In this Section:
Aptos’s design choices as a compromise between reliability and performance, sitting between Solana and Ethereum
We present the High-performance Trilemma among performance, reliability, and efficiency.
To builders, the future is use-case optimization. We propose a 3-question playbook to help builders choose infrastructure.
For more than an entire year, Solana remains the only major name in the high-performance L1 niche. Now we have Aptos, developed by the former team of Facebook’s Libra, and funded by a16z, Tiger, Multicoin, and FTX. Multicoin and FTX are notably also Solana heavyweights. Aptos recently made headlines as they claimed 160,000 TPS, clearly positioning themselves as a Solana competitor.
That’s why we spent so much time dissecting Solana: this is the best perspective to understand and contextualize Aptos:
Recall from the last section that Ethereum is optimized for uptime: ETH spends a lot of redundancy to prepare for the worst case, so it’s almost impossible to halt Ethereum with an attack. Solana is optimized for best-case performance, spending less on redundancy thus making the network less reliable in extraordinary cases.
Aptos tries to take a step back from Solana in the redundancy dilemma. Here are some key design choices as we put them in context:
Aptos design choice 1: 16-core server-level CPU. It’s a middle ground between Solana’s 4096 GPU cores and Ethereum’s 1 CPU core. Aptos may not be as fast as Solana when processing highly parallelable tasks. Each of Aptos’ CPU cores is much more performant than Solana’s GPU core/multiprocessor, so in the case of logically sequential transactions like NFT mint wars, Aptos may handle them much better than Solana.
Aptos design choice 2: O(n) best case and O(n^2) worst case. Relative to Solana, Aptos tries to make its network more resilient by adding redundancies. Instead of trying to get to Solana’s extreme O(log n) sublinear redundancy, Aptos settled for O(n). At each round of consensus, Aptos requires all non-leader nodes to sync extra data should the current leader fail and other nodes need to take over. Aptos also didn’t try to split-and-verify blocks as the split creates extra work when things go wrong. The result: when the leader does fail, Aptos turns less messy than Solana.
Comparison: Aptos’ best-case performance is not as good as Solana’s, but Aptos is much more acceptable in the worst-case — O(n^2) compared to Solana’s O(n^4). If we map the five performances together, they present a nice sandwich putting Aptos (purple) right between Ethereum (blue) and Solana (green).
Aptos design choice 3: Crazy hardware. Some of you may have seen Aptos claim 160,000 TPS and wonder why I say its best-case performance is not as good as Solana.
Note the Aptos hardware requirement: all their tests are run on AWS EC2 instances with 16-core server-level CPUs. Aptos also publicly recommended running their nodes on Google Cloud Platform instead of private computers.
The 160,000 number is the result of lab tests on ~100 permissioned nodes — TPS is all but sure to be lower in more complex actual production with more nodes. Aptos internal tests also show as the network scales to more nodes, its performance will come closer to or even lower than Solana’s current 65,000 TPS.
Here’s a quick summary of Aptos, Solana, and Ethereum key tech specs for your notes:
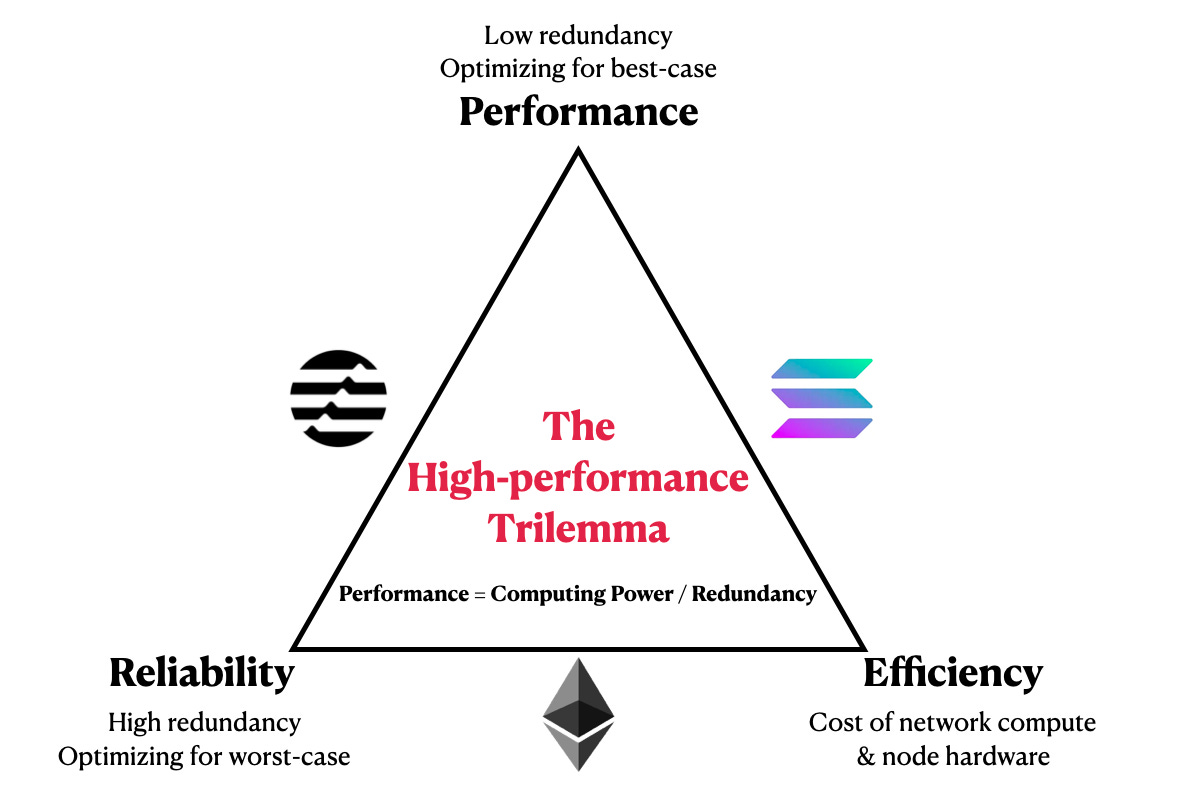
Putting everything together: the high-performance trilemma
Expanding on the redundancy dilemma, and taking Aptos’ yet higher hardware requirement into consideration, we present a rehash of Vitalik’s blockchain scalability trilemma: the high-performance trilemma.
In this trilemma, the three first-principle qualities that cannot co-exist are:
Reliability: strengthen network uptime by spending more computing on redundancy
Performance: strengthen network throughput by spending less computing on redundancy
Efficiency: the only way to mitigate reliability and performance is to acquire more computing to spend on both
Among Ethereum, Solana, and Aptos,
Ethereum chose Uptime and Efficiency, so it spent limited compute on redundancy, resulting in slow Performance.
Solana chose Performance and (relatively) Efficiency, so it spent limited compute on best-case performance, limiting redundancy which can negatively impact Reliability.
Aptos chose Uptime and Performance, so in order to have enough computing to cover both, Aptos has to opt for server-based nodes and give up Efficiency.
The design philosophy of Aptos is quite silicon-valley: stress on user-friendliness, not on decentralization. Early descriptions indicate that Aptos may integrate a high-level user account system with password recovery. Aptos is certainly not the most decentralized blockchain by any measure. It is not aiming for ideological purity. The 200 million seed ticket from a16z and Tiger puts some real money and resources behind that somewhat contrarian vision.
What does it all mean for investors and builders? Use-case optimization.
No Maxis.
No Maxis.
No Maxis.
Optimize for your use cases.
Even AWS offers dozens of database configurations for different use cases because there is no one-size-for-all solution. Blockchains are databases.
Being a maxi may help one profit by taking short-term risks in a fast-growing speculative market, but tribalism is not good for real value discovery and buidl. A good investor and builder should be realistic about trade-offs and really understand your use cases, instead of indulging in shilling, bubbles, and PR-speak.
Now we only have the broadest contour of things. Both Solana and Aptos will undergo a lot more bugs, outages, fine-tuning, and patches. Solana will be down again, and so will Aptos. But it doesn’t change their status as the top contenders to solve the lucrative high-performance L1 problem.
For builders: Know at least three things:
Your use case: what’s critical and what’s just nice to have
The trade-offs and DNA of the infrastructure you wanna work with
The cost and benefit of mix-and-match: Cross-chain solutions and risks, a previous article by The Anti Ape. Great dApp utilizes chains, bad dApps are consumed by their chains.
For investors: Aptos will release public testnet and tokens in 2022. This means Solana’s monopoly in the high-performance space is ending soon. We expect Solana’s token price to experience some selling pressure as investors diversify their bets in the high-performance vertical. But it’s too early to call the winner.
In any case, Aptos looks like a worthwhile challenger to Solana as it tries to balance Solana’s chronic reliability problem with another set of trade-offs. It remains to be seen whether the Aptos team can execute well, and whether they can challenge Solana’s 2-year ecosystem headstart.
General disclaimer: No investment advice. The technical illustrations are to the best of the author’s knowledge at the time of publication. The essay necessarily contains important omissions and approximations for the simplicity of the narration. Observations and assumptions may need to be updated or corrected as projects release more information about their protocols. We appreciate any discussions, suggestions, and corrections.
Scratch area.
Note 1: we have made some omissions on technical details to simplify the bigger-picture. Two key omissions worth discussing: 1. we use thread and core interchangeably in narration because they conceptually map quite well: a software thread in a virtual machine is executed by a physical core on a chip. We are aware of hyperthreading technologies but we believe they are not a key detail here. 2. Our claim on EVM being single-threaded is to highlight its lack of native parallelism. We choose to ignore the fact that some auxiliary computations may be parallelized because we don’t believe these minor optimizations have a major impact on Ethereum’s performance.
Note 2: n^3, 67%, dominant factors.
Note 3: Use of TPS and limitations
Thanks for reading The Anti-Ape! Subscribe for free to receive new posts and support my work.